The Star-Schema, basically, is a data model in which, at the center, we’ve got the Fact Table and around and connected to it we’ve got the Dimension Tables. It’s a middle-term when it regards to normalization/denormalization, it’s not fully denormalized and it’s not fully normalized (once the dimensions could have duplicated values in a column, ex: brand on the product table).
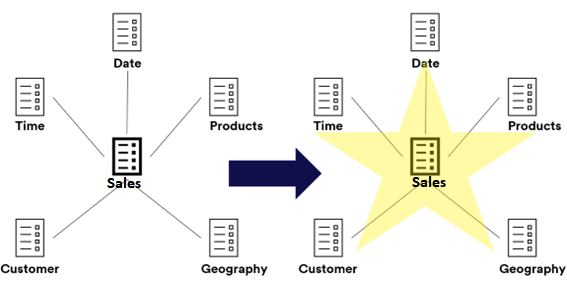
In Power BI, when creating a Star Schema, we’re ALWAYS looking for:
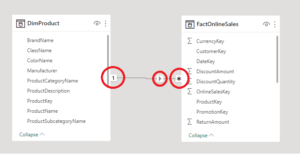
- one-to-many relationship, between the Dimension (1-side) and the Fact (many-side).
- relationships to be SINGLE-DIRECTION.
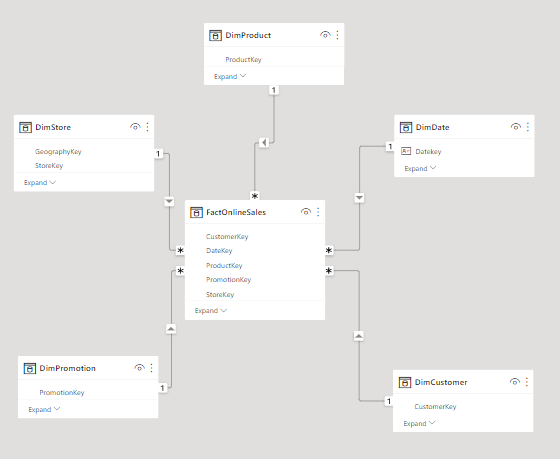
The final goal is to achive a data model that looks like the one below. Achieving a model like this will definitely make your Power BI Journey much easier:
Before ending this section, I would like to make a few remarks:
Avoid at any cost to have MANY-TO-MANY relationships, this WILL degrade the model performance (unless you know VERY VERY well what you’re doing).
- Avoid at any cost to use BI-DIRECTIONAL relationships, this will degrade model performance and will generate AMBIGUITY on the model, causing wrong calculations (non-deterministic nature). That are two scenarios which this the bi-directional relationship are allowed to be used: on a bridge table (more details along this article) and at the “leaf” level of a Snowflake Schema (not ideal, but ok).
- One-to-One relationshiop could be merged into a single table. If this relationship is only by chance, you should enforce the many side by editing the relationship properties.
Guarantee that all keys on the Fact Table have their reference on the Dimension Table. Having a key (ex: a brand) in the Fact table which doesn’t have a pair on the Dimension table is considered a Data Integrity issue (that’s why many of the slicers has a “blank” on it. Or the “blank” row in a matrix visual).
You can check the data integrity of your report using DAX Studio.
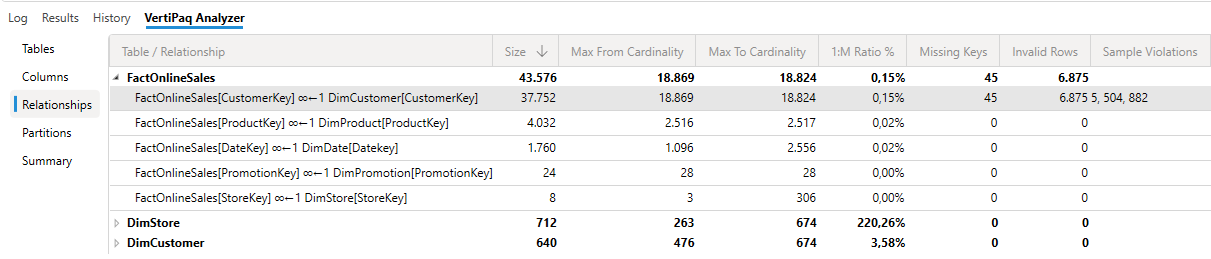
One of the most important tables in any model.
In order to perform “Time Intelligence” calculations (using DAX functions like DATESMTD(), SAMEPERIODLASTYEAR(), DATESYTD()) we must have a date table on our model which has the day as the table key (i.e., one day per row with no duplicates).
Also, is important to have this table setup correctly and disable the “Auto Date/Time” on the Power BI options. Doing this, you can guarantee that the size of your model is not affected and avoid to use dates from other tables/columns as dimensions on your visuals (thus, avoiding generating wrong values).
In order to disable the “Auto Date/Time”, just go into the Option tab in Power BI and uncheck it from Global > Data Load tab and Current File > Data Load (remember to re-open your PBI file to the effect of the changes):
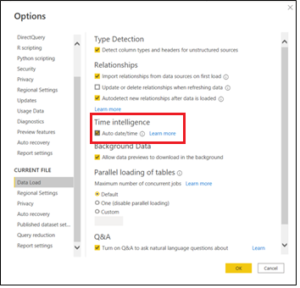
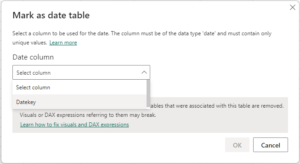
A very important step is, after uploading the Date Table, to mark it as the “Date Table” of the model, thus, the engine will now how to build the query plan when using the Time Intelligence DAX Functions.
More about the Date Table, check this article
A very common scenario that you might face (if you haven’t already) is to link a dimension table with a fact table when they have different “granularities”, especially if the fact table has a higher granularity than the dimension.
The granularity of a table is the minimum detailed level we can reach in a dimension. For example, on a date table, it would be the date itself. In a time table, it can be the combination of Hour and Minute (17:30) or even just the second.
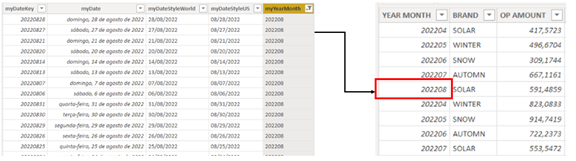
The complication appears when we’re trying to connect a Dimension Table to a Fact Table, in which the Dimension table is MORE detailed than the Fact Table (example, connect a Date Table that has a daily grain with a budget table containing a year-month grain).
Two very common strategies people are used to do are:
-
- A Many-to-Many bidirectional relantionship (which should by HIGHLY avoided)
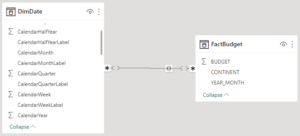
fig 10: Many-to-Many relationship for tables with different grains - Creating a column on the fact table that “tries” to reference the lower grain on the dimension using a Onr-To-Many relationship (mainly applied when we’re working with date granularity)
fig 11: budget table “simulating” a lower grain
- A Many-to-Many bidirectional relantionship (which should by HIGHLY avoided)
Despite of this second option not being the most recommend one, this should not cause big performance issues. It could only generate some hard work to build the DAX Measures.
The best approach to deal with this scenario is to build a “Bridge” (or Factless) table. This table must contain only one column representing exactly the grain level that is common for both tables.
In our example, it is the Year-Month. Then, we build the relationship as following:
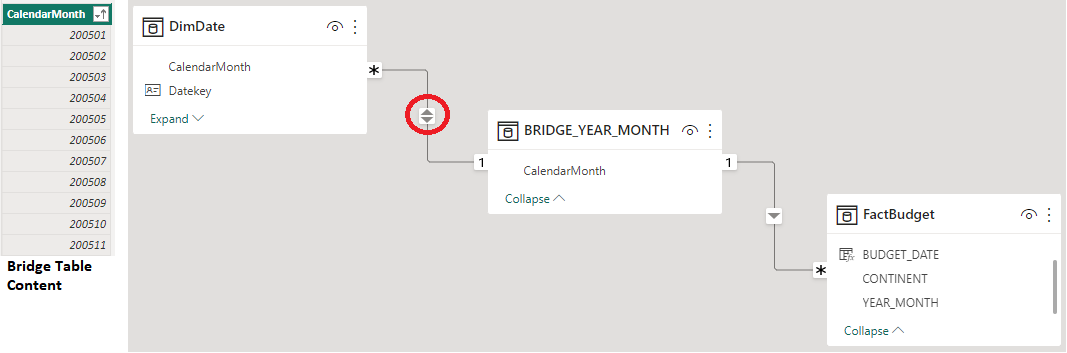
An attention point here is the bi-directional relationship between the DIMENSION table and the BRIDGE. This is the only time in a Power BI Star Schema model that we should use the bi-directional relationship.
The reason for this is very straightforward, we want to propagate the filter on the Date Table up to the higher grain Fact Table. In other words, we want the Date Table to filter the Bridge Table and the bridge to filter the higher grain Fact Table. The only way to do that is enabling the bi-directional filtering.
Despite of this probably causing some performance drawback (once that the bridge and the dimension will have to filter each other, generating more queries than an ideal case of one-to-many relationship), the tables used in this situation are usually small, with a low cardinality, thus, this drawback is not noticed by users.
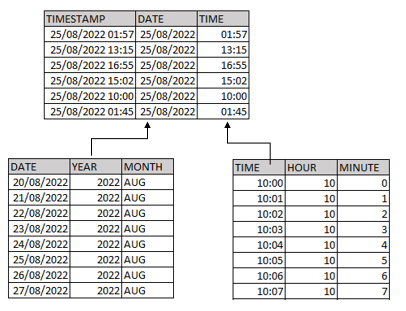
When we’ve got a Fact Table containing a Timestamp, example, a sensor data acquisition, we should break the timestamp into two columns: a date only and a time only.
Then, we should import two dimensions tables, one for Dates and another for Time, creating a one-to-many relationship with the Fact Table: